Congrats on Your Agent Memory System. Here's Where It Falls Apart.
Across seven public agent memory systems, the same five architectural decisions keep showing up, along with the same five cracks. Those cracks are where the costly failures tend to live.
- Published
- Reading Time 12 min read
- Tags
I looked at seven teams that shipped memory systems for agents. A research lab, a hyperscaler, a YC startup, an open-source project, a CLI tool, a framework consultancy, and a managed memory platform. No shared playbook between them.
Across those seven systems, the same five decisions kept showing up. The same five cracks did too.
Convergence isn’t proof anyone is right. Whole fields can agree and be wrong together. But when seven groups with little in common keep arriving at the same architecture, the overlap tells you something real about the shape of the problem. The disagreements tell you where the work isn’t finished. The cracks tell you where it breaks in production.
This post explores all three.
The cast, with links for anyone who wants to go read the source:
What follows is my synthesis from these seven public systems, not a claim that the whole field has settled on one design.
- LangGraph. Thread-scoped short-term memory (one conversation, one thread) paired with namespace-scoped long-term memory (one namespace per user or project).
- OpenAI’s Agents SDK. By default, sessions prepend stored conversation history before each run, with long-term memory left to whatever store you pair with it.
- Claude Code.
CLAUDE.mdfiles and auto-memory, treating instructional memory (how to work, not just what you said) as first-class. - Microsoft AutoGen. Memory as a protocol (
add,query,update_context,clear,close) with an explicit context-update step that runs right before each model call. - Mem0. Managed memory (hosted service you call into) with extraction, conflict resolution, and a dashboard.
- Letta. Composable memory blocks (small, named chunks of memory) attachable and editable at runtime.
- Google Vertex AI Memory Bank. Managed long-term memory with revisions enabled by default, TTL controls, and IAM conditions (Google’s access-control system) layered over scopes.
The five decisions
1. Session state and durable memory are never the same system
Cleanest signal in the set. Across the seven systems I reviewed, “what was said in this conversation” and “what should outlive this conversation” are handled as separate concerns. They look similar on the surface. The access patterns, lifetimes, and failure modes aren’t.
LangGraph has thread-scoped checkpoints for one and namespace-scoped stores for the other. OpenAI’s Agents SDK auto-prepends and auto-appends turns but explicitly leaves durable memory to whatever you pair with it. Mem0 splits conversation, session, user, and org. Letta pins memory blocks in the prompt and persists messages separately, retrievable but not auto-replayed. Vertex AI Memory Bank treats session history and long-term memory as distinct resources with different lifecycles. Claude Code starts with a fresh context window and handles continuity through CLAUDE.md and auto-memory instead of replaying transcripts.
The underlying point is the same. Compaction is session hygiene. Promotion is a separate decision with separate policy. Conflate them and you break both.
2. Retrieval gets its own phase, right before the model call
Across these seven systems, retrieval shows up as an explicit assembly or context-update step immediately before execution. Not as a side effect of some storage layer. A governable step.
AutoGen names this most cleanly. Its memory protocol has a dedicated update_context operation whose only job is mutating the active context before the model runs. OpenAI Agents does it during input assembly. Letta injects attached blocks into the system prompt at run time. LangGraph reads state at every step boundary. Mem0’s standard flow is query → assemble → prompt on each call.
This matters because governable retrieval is where all the policy actually hangs. Scope filters, staleness checks, confidence thresholds, explanation payloads. If retrieval is hidden inside the model call, none of that is possible. If it’s a step you own, it’s a step you can instrument.
# Illustrative pseudocode based on AutoGen's Memory protocol.
# `update_context` is the hook where memory mutates context before the model runs.
class MyMemory(Memory):
async def update_context(self, ctx: ChatContext) -> UpdateContextResult:
hits = await self.query(ctx.last_user_message())
ctx.add_system_message(format_memories(hits))
return UpdateContextResult(memories=hits)3. Promotion needs policy. No blind append.
The weakest systems dump raw transcripts into durable memory and let retrieval sort it out later. The strongest ones treat every promotion from session to durable as an explicit pipeline with gates at each step.
Mem0 runs an extract-resolve-store flow on add: infer structured memories, detect conflicts with existing entries, resolve with “latest truth wins,” then store. The inferred memory has different authority than the raw transcript it came from. Claude Code’s auto-memory watches for user corrections and repeated preferences, not every observation that goes by. Letta uses editable blocks rather than auto-promotion. Agents write blocks when something deserves it. Vertex AI Memory Bank runs extraction and consolidation as async background jobs, off the hot path.
The shared insight, compressed. Raw experience is not memory. Memory is what survives a promotion policy.
4. Scope is a first-class retrieval and safety control
Across the seven systems, scope is treated as part of the query shape or attachment model, not a filter slapped on after the fact.
Mem0 is built around entity-scoped memory via identifiers like user_id, agent_id, app_id, and run_id. LangGraph’s stores are namespace-scoped, typically composite (user plus project). Letta’s attachable blocks mean an agent’s effective memory is the union of whatever blocks are currently attached. Vertex AI Memory Bank enforces identity-scoped isolation and supports IAM conditions that can express “this principal can read memories where scope.project = X.” Claude Code loads managed, project, user, and local instruction sources with more specific guidance typically having the last word in practice.
The convergent rule in the systems above. Scope must fail closed. If the scope can’t be resolved, refuse. Don’t widen. The reason isn’t just relevance. It’s privacy. Silent scope-widening is how memory leaks across projects, across users, across agents. “Just one more fallback” becomes “why did the agent just tell me about my coworker’s project.”
# Fail-closed scope: no resolvable scope = refuse, never silently widen
if not user_id:
raise ScopeError("user_id required; refusing rather than widening to global")
results = store.search(("memories", user_id), query=q)5. Pinned memory beats retrieval for top-priority facts
Every system in this set that handles long-running agents ends up with a pinned lane. Memory that lives in the prompt unconditionally, not filtered through ranking.
Claude Code loads CLAUDE.md and auto-memory at session start. Not retrieved. Present. Letta’s “core” blocks are injected directly into the system prompt. Other memory is retrievable but not pinned. OpenAI Agents session items auto-prepend before each run, subject to history limits or compaction if you enable them. LangGraph reads state at step start unconditionally.
Why retrieval is insufficient for the high-priority layer: retrieval is ranking, and ranking has variance. For preferences that must always apply and policies that must always fire, variance is the enemy. Pinning removes the variance by making the memory part of the prompt’s base instead of its results.
The tradeoff is obvious. Pinned memory costs tokens every call. So these systems tend toward a small pinned layer and a larger retrieved layer. Which is MemGPT’s tier model again, just dressed differently.
Each team’s distinctive decision
What makes each system its own thing:
- LangGraph. Cleanest public split between short-term memory (per conversation) and long-term memory (per user or project). On top of that, an explicit taxonomy: semantic (facts), episodic (events), procedural (how-to).
- OpenAI’s Agents SDK. Continuity first. By default, sessions replay stored history into the next run, with optional history limits and compaction. Durable memory is left to whatever store you pair with it.
- Claude Code. Instructional memory as first-class.
CLAUDE.mdtreats repo conventions and workflow rules as a memory class in their own right, separate from facts about the user. - Microsoft AutoGen. Memory as a formal protocol. Five operations any memory implementation has to provide:
add,query,update_context,clear,close. Theupdate_contextoperation is the explicit phase where retrieval meets the prompt, called right before the model runs. - Mem0. Managed memory as a product surface. One hosted service handles extraction (pulling memories out of conversation), conflict resolution (when two memories disagree), scoped search, and a dashboard. One flow instead of seven you assemble yourself.
- Letta. Memory as composable objects. Blocks can be pinned in the prompt, attached to an agent, shared across agents, and edited at runtime by the agent itself. An agent can rewrite its own memory mid-task.
- Google Vertex AI Memory Bank. Memory with operational rigor. Revisions are enabled by default (and can be disabled), TTL controls how long memories or revisions persist, deleted memories have a limited recovery window, and IAM conditions support access rules like “this principal can only read memories where project = X”.
Where they actually disagree
Convergence gets the headlines. The interesting part is where the seven systems still don’t agree, and three disagreements have real weight. Each one is a choice that changes how the system behaves day to day, not just how it reads on a docs page.
Instruction memory vs. fact memory
Claude Code is built around instructional memory. How to behave, repo conventions, workflow rules. Mem0 is built around factual memory. The user likes X, the project decided Y. Letta spans both through blocks. Most other systems implicitly treat memory as facts and leave instructions to the system prompt.
<!-- CLAUDE.md: instructional memory, loaded into every session -->
Use pnpm, not npm.
Write tests with Vitest, not Jest.
Never use em dashes in copy.# Illustrative pseudocode: factual memory, extracted from conversation and scoped to a user
m.add("User prefers TypeScript over JavaScript", user_id="alice")
m.add("Project 'Bakin' chose AntflyDB over LanceDB", user_id="alice")This matters. Retrieval logic, promotion rules, and editability requirements are genuinely different between the two. A preference can be superseded. A workflow rule has to fire every turn. Systems that collapse them struggle in both directions. Instructions get forgotten in long tasks. Facts get rigidly reapplied when they shouldn’t.
Runtime-owned vs. store-owned governance
Where does lifecycle policy live.
Store-owned. Mem0 and Vertex put promotion, supersession, TTL, and extraction inside the memory store. The agent calls add and search and the store handles the rest.
# Illustrative pseudocode: the store decides what to extract, dedup, and expire
m.add("User prefers concise responses", user_id="alice")
results = m.search("response style", user_id="alice")Runtime-owned. LangGraph and AutoGen put policy in the runtime. You decide when to write, what to extract, how to rerank.
# Illustrative pseudocode: you own the extraction, the write, and the query shape
if should_remember(message):
await store.aput(
("memories", user_id),
str(uuid4()),
{"text": extract(message), "kind": "preference"},
)
memories = await store.asearch(("memories", user_id), query=current_context)Hybrid. Letta and Claude Code do both. Some lifecycle is agent-driven (agents editing their own blocks), some is infrastructural.
# Illustrative pseudocode based on Letta's current memory editing tools.
memory_replace(
block_label="persona",
old_text="Generalist engineer.",
new_text="Senior engineer. Prefers Go. Concise responses.",
)Neither is wrong. Store-owned is easier to adopt, harder to customize. Runtime-owned is more flexible, more work per deployment. The choice has implications all the way up to who owns correction flows and provenance visibility.
User-facing visibility
Widest gap in the field.
ChatGPT has polished end-user memory controls. Inspect, delete, disable, temporary mode. Mem0’s OpenMemory UI markets browse, tag, and manage flows. Letta exposes blocks as inspectable objects. Vertex exposes revisions and IAM but is operator-facing, not user-facing. AutoGen, LangGraph, and the Agents SDK leave user-facing memory UX almost entirely to the application developer.
This is one of the first things I wanted to get right when building Bakin for OpenClaw. An agent memory system is only useful if you can see what’s in it and edit it.
The forcing function came from a rename. The project started as “beacon.” It got renamed to “bakin.” My main agent, Roscoe, could not let beacon go. Ran in loops. I tried AGENTS.md. Skills files. Escalations in the system prompt. Same behavior every time.
So I built a view over the memory store. Session, markdown, and durable tiers in one place, searchable and editable. First query: “beacon.”
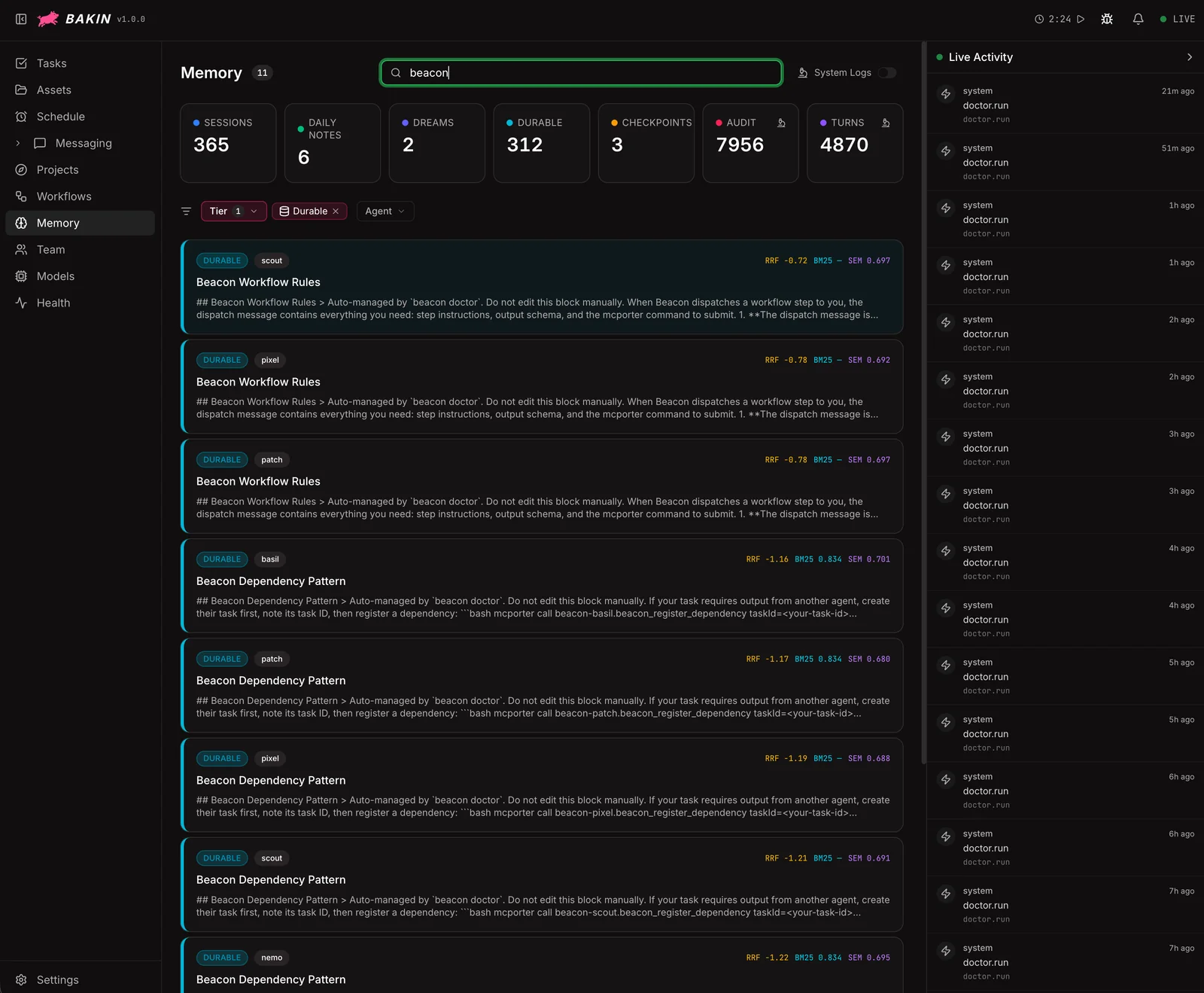
Dozens of beacon references sitting in the durable store across scout, pixel, patch, basil, nemo. Auto-managed by beacon doctor. Pinned, weighted, surfacing every turn. Prompt engineering was never going to outrank that. Once I could see it, the fix was thirty seconds.
Infrastructure has advanced much faster than the interfaces. This one’s not close.
The five cracks everyone has
Across the seven systems, the same gaps show up repeatedly.
- Scope and isolation. Most systems have scopes. Fewer make scope resolution, fail-closed behavior, and cross-scope leakage inspection truly first-class.
- Lifecycle and supersession. Most systems can store a new fact. Fewer can cleanly model “this replaces that,” mark records stale, surface conflicts, and preserve visible revision history.
- Provenance and “why recalled.” Users and operators want to know where a memory came from and why it surfaced. Almost nobody exposes this as a queryable or visible object.
- Summary artifacts treated as canonical. Compactions, reflections, and synthesized briefs often get reused as if they were primary sources, even when they have already dropped nuance or preserved the wrong branch.
- Promotion without authority checks. Hypotheses, drafts, tool paraphrases, and model inferences get promoted into durable memory without enough checks on truth status, source authority, or applicability.
These aren’t nice-to-haves on someone’s backlog. They’re where many of the production bugs that matter actually live.
What breaks when the cracks open
Take each crack in turn and the recurring failure modes fall out immediately. The same shapes show up across systems, which is the strongest evidence the cracks are structural, not implementation details.
Scope crack, open. Silent scope-widening pulls another user’s preference, another project’s decision, or another agent’s local note into the wrong session. The scope filter matched nothing, a fallback widened the search, something returned, and it was wrong. Nobody noticed until a cross-customer note surfaced. Or a “temporary” session still contributes to recall traces, flushes, or dream promotions, so an ephemeral conversation quietly changes future behavior. That one destroys user trust faster than any other failure in this category, because it breaks an explicit promise.
Lifecycle crack, open. The user changes a standing preference and the old one still ranks highly, so the agent keeps writing in the old style. The project architecture shifted, but last quarter’s pinned decision brief is still in the retrieval set, and the agent implements reverted patterns. The source file changed and the memory didn’t, so the agent cites a stale quote as current truth. The user says “that’s wrong” and the agent adapts the current turn, but the underlying record stays untouched, so the same wrong fact resurfaces next week. That last one is what users mean when they say “I feel like I’m telling it the same thing over and over.” Same shape as the beacon-to-bakin story earlier. The rename landed in the prompt. The corrections landed in the current turn. The durable store was never touched, so “beacon” kept surfacing every run until I opened the memory view and cleaned it out.
Provenance crack, open. The extraction pipeline writes an inferred claim as a fact, and months later the system “remembers” something the user never said. A brainstorm-phase hypothesis ranks beside a user-confirmed preference and gets cited as settled knowledge. A tool result gets paraphrased into something stronger than the source supported. The memory is retrievable, but nobody can tell where it came from or whether to trust it.
Summary crack, open. A long session gets compacted after an earlier plan was rejected. The summary preserves the original plan and silently drops the reversal. Future turns revive the wrong branch. Recursive summary-of-summary cycles smooth away the hedged qualifiers until the brief reads cleaner than the evidence ever did. The same synthesized summary gets restated across enough turns that agents stop checking primary sources, and the summary becomes de facto canonical. This whole category is one mistake in different clothes. A derivative artifact treated as canonical.
Promotion crack, open. A temporary working note appears often enough to get promoted, and a one-off debugging assumption becomes a durable rule. Semantic similarity ranks an older but textually similar note above the newer explicit decision record. A dreaming pipeline promotes a popular but misleading snippet because it scored high on frequency and nothing else checked its authority.
The whole corpus of memory bugs compresses to one line.
“Wrong thing” is provenance failures plus summary artifacts being treated as primary truth. “Wrong status” is lifecycle. “Wrong scope” is scope. “For too long” is what happens when correction, supersession, and expiry fail. Promotion without authority checks is how the wrong thing gets durable status in the first place. Those five cracks are the mechanisms behind the whole failure pattern.
What the cracks tell you to carry on every record
Read as design constraints, the cracks give you the minimum shape I’d want in any serious durable memory record.
class, because a hypothesis should retrieve differently from a factscope, because fail-closed is the only defense against silent cross-contaminationorigin, because user-stated and model-inferred need different trust weightsstatusofactive | stale | superseded | conflicted | archived, because “it’s still in the store” is not the same as “it’s still true”confidence, because not all memories deserve equal retrieval weightfreshnessorlastValidatedAt, because memories go stale even when correctsourceRefwith source id, path, version, and quote span, because without provenance you cannot debug anythingsupersedesandsupersededBy, because “this replaces that” is the most common operation you’ll want latercreatedByandcreatedFrom, because knowing who wrote a memory is a prerequisite for deleting it correctly
Put them together and you get the minimum shape I’d want every serious durable memory record to carry.
interface DurableMemory {
id: string;
class: "fact" | "hypothesis" | "instruction" | "preference";
scope: { userId: string; projectId?: string; agentId?: string };
origin: "user-stated" | "model-inferred";
status: "active" | "stale" | "superseded" | "conflicted" | "archived";
confidence: number;
lastValidatedAt: Date;
sourceRef?: {
docId: string;
path: string;
version: string;
quote: string;
};
supersedes?: string;
supersededBy?: string;
createdBy: string;
createdFrom: "extraction" | "user-input" | "tool-output";
}None of these are theoretical. Each maps to a specific failure above that omitting it causes.
Why this frame matters
The field agrees more than you’d think on the shape of memory. Multi-tier. Typed. Scoped. Retrieval as an explicit step. Policy on promotion. Where it still splits: governance, the specifics of that promotion policy, and how much of the memory logic belongs in the runtime versus the store.
If you’re evaluating or building one of these systems, the useful question isn’t “does it have memory.” Across the seven systems above, the same five decisions recur. The useful question is which of the five cracks is still open, because that’s where you’ll pay the failure tax.
On This Page
Rate